Dans le genre il y a :
+ Brook+ qui est la version "cuda" d'ATI, moins aboutie que cuda.
+ TBB et Cilk+ qui sont des extensions du C développées pas Intel (en open-source maintenant)
+ les langages PGAS (
http://en.wikipedia.org/wiki/Partitioned_global_address_space) : Coarray-Fortran, UPC, X10, Chapel, Fortress
Quelques précisions :
+ OpenHMPP est la version libre du logiciel commercial de CAPS entreprise HMPP. A la bas HMPP est une extension du C, via des pragmas, pour écrire du code qui va s'exécuter sur des accélérateurs (GPGPU, coprocesseurs...). Si tu veux qu'une fonction s'exécute sur la GPU, tu l'encapsules par les bons pragmas. La fonction sera restrancrite dans un langage cible, par exemple CUDA pour un GPU NVidia, ou OpenCL pour un GPU ATI. Si le GPU est disponible, ta fonction va s'y exécuter, sinon c'est la version proc qui prend le relais. Tu peux préciser quelles sont les variables que tu veux transférer sur la carte et quelles sont celles que tu vas rapatrier. Il peut aussi y avoir des variables persistantes sur le GPU. Tu peux aussi construire un prototype de la fonction destinée à s'exécuter sur le GPU et la modifier pour l'optimiser... La stratégie de mettre HMPP en open source est clairement de populariser ce pseudo langage. Ca ressemble pas mal à OpenMP. La gestion de systèmes multi-GPU/accélérateur est prise en compte
+ OpenACC est une tentative de normalisation issu d'un groupe de réflexion d'OpenMP sur les accélérateurs, en vue d'une intégration dans la norme 4.0 d'OpenMP. C'est aussi un coup d'éclat, du genre "si on ne nous écoute pas à l'intérieur ou si on trouve que ça ne va pas assez vite, alors on déborde la comm à l'extérieur pour montre combien on a raison." Ca n'a pas l'air mal. Les transferts pourront soit se faire automatiquement, soit être préfetchés par le codeur. Par contre je ne sais pas ce que tu entends par "RAM Locale GPU, RAM Globale GPU, RAM private GPU" ? Tu parles de la mémoire texture et autres ? Dans un contexte de programmation parallèle avec des accélérateurs et coprocesseurs, le programmeur s'intéresse uniquement à la mémoire globale. Ceux qui veulent utiliser la mémoire de "texture" par exemple devront passer par le langage spécifique au proc visé. La gestion de systèmes multi-GPU/accélérateur est aussi prise en compte.
A suivre aussi : Intel MIC. Un futur coprocesseur qui utilise les langages de programmation traditionnels.
Le principal inconvénient des GPGPU est le modèle de programmation qui est basé sur du SIMD, mais coté "data". Si tous les threads ne font pas le même travail en même temps, tu as une perte de performance (typiquement un if dans une boucle). Et il faut des milliers de threads pour tirer de la perf. J'aime bien cette page qui résume ce qui marche, ou pas, sur un GPGPU :
http://lava.cs.virginia.edu/gpu_summary.html
Pour la roadmap d'ATI, je dirais que ça va dans le bon sens. Le GPU ne peut pas rester sur un port PCI avec les taux de transfert qu'on connait. Le seul hic est peut-on se servir du GPGPU pour faire autre chose que ce qui est du domaine de l'imagerie ? Et quid de la norme IEEE danns les GPGPU ? c'est bien beau de faire des calculs rapides, mais si le GPGPU fournit des résultats différents du CPU, certaines applications n'ont aucun intérêt à tourner sur le GPGPU.





 pas seulement de la routine modifiée, mais de toute l'appli.
pas seulement de la routine modifiée, mais de toute l'appli. Sans parler des mémoires _locale à une compute unit:
Sans parler des mémoires _locale à une compute unit: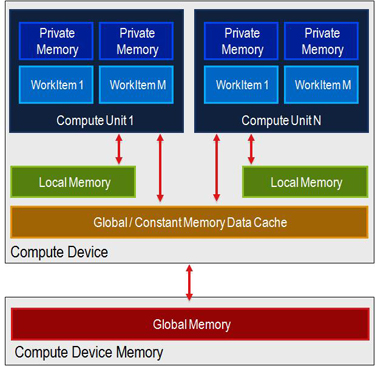
 )
){kind=link}
{kind=link}